
5 Assisting Patrons with Quantitative Research
Quantitative research requires patrons to make choices. Each choice affects the next and can determine the success or failure of the project. Law librarians can assist patrons in making informed choices during the formulation, design, execution, and reporting of quantitative research. Little of this assistance requires an advanced degree in statistics or a quantitatively-focused discipline such as Economics. In fact, just as we avoid giving legal advice, librarians stop short of making methodological choices for our patrons. Rather, we guide them to the terminology and tools that they need to conduct good research.
Quantitative methods vary from experiments to surveys to content analyses (see Chapter 4 for definitions; Jenkins-Smith et al., 2017). Each project requires different resources, such as a distribution system for surveys (e.g., Qualtrics) or digitization for print content analysis (see Hicks, 2019; Lillian Goldman Law Library). But all quantitative research involves questions of whether the subject matter is quantifiable, what data to collect, and how to collect/capture, manage, analyze, and report the data (social) scientifically. Law librarians can help patrons navigate these questions.
Chapter learning objectives
- Ask questions to see if quantitative research is the best approach for a project
- Understand unit of analysis, sampling, instrument, validity, reliability, and levels of measurement
- Identify common research survey weaknesses
- Explain the data lifecycle
Abbreviations and specialized terms
causation, content analysis, Covidence, data lifecycle, dependent variable, descriptive research, double-barreled, generalize, incremental data, independent variable, inferential statistics, intercoder agreement/reliability, interrater agreement/reliability, interval-ratio data, levels of measurement, mean, median, mixed-methods research, mode, mutually exclusive, nominal data, non-exhaustive, ordinal data, original data collection, overlapping, population, qualitative research, Qualtrics, quantitative research, reliability, representativeness, research instrument, sample, sampling, sampling frame, summary statistics, survey distribution system, systematic review, triangulated research, true score, unit of analysis, validity
Should the Research be Quantitative?
Empiricists use a variety of methods to study law, government, and justice, some quantitative, some qualitative, and some descriptive (e.g., entire article is a literature review but not a systematic review). For instance, Mark A. Hall and Ronald F. Wright quantitatively analyzed judicial opinions to demonstrate the benefits of content analysis for legal-text research (Hall & Wright, 2008). Separately, professor Hall was part of a qualitative team that conducted focus groups to determine how immigrants were affected by state preemption of protective municipal laws (Mann-Jackson, Simán, Hall, Alonzo, Linton, & Rhodes, 2022). Professor Wright’s recent projects have been methodologically varied, and include a descriptive literature review on prosecutor-led diversion programs (Wright & Levine, 2021) and a quantitative analysis of prosecutor legislative activity (i.e., lobbying; Hessick, Wright, & Pishko, 2022). Accomplished empirical researchers like professors Hall and Wright select the methods that best match their project goals and resources. Law librarians can ask patrons four questions to aid in their selection of a quantitative, qualitative, descriptive, or mixed-methods research approach.
5.1 Overview of systematic reviews
Most social science journal articles have a literature review that covers seminal publications, major debates, and studies similar to the article. A small subset of research texts also feature a systematic review. A systematic review is a type of original research, somewhat analogous to content analysis, in which a dataset is created through repeated extraction of information from documents. The researchers leading a systematic review pose a narrow research question that can be answered by published research. The research question will include words that screen out, or exclude, non-pertinent studies while allowing in all pertinent research. Pertinent published research is the population under study. The systematic reviewers attempt to find all pertinent published research. Before reviewing the research, they develop a procedure for extracting the same pieces of information from every document. For biomedical research, where systematic reviews are the gold standard, commonly extracted information includes: number of study participants, the health intervention (e.g., a specific chemotherapy drug), and treatment efficacy (e.g., 5-year survival rate). A number of software programs, including Covidence, can be used to systematize this data collection. After data collection, most researchers disclose their systematic process—including search strings—and report their findings in a table that enables readers to compare individual studies to each other. The researchers also draw conclusions from the research corpus. For instance, in a systematic review of the needs of rural breast cancer survivors [BCS] in the U.S., researchers found that the “[s]upport networks of rural BCS consisted of family, church family, friends, and co-workers” and that “transportation [w]as a barrier to accessing survivorship support and education” (Anbari, Wanchai, & Graves, 2020, p. 3527). In addition to systematic reviews, researchers conduct scoping, rapid, and other reviews (see Roth, et al.).
First, law librarians can ask: Are you interested in causation in this study? Researchers can study a phenomenon deeply with or without a causation focus. For instance, economist Donna Roberts published an influential descriptive article in 1998 assessing the early effects of the World Trade Organization’s Agreement on the Application of Sanitary and Phytosanitary (SPS) Trade Regulations (e.g., pesticide regulation; Roberts, 1998). In the 2010s, she co-authored related articles, including a descriptive analysis of the effects of SPS regulation on health promotion (Josling, Orden, & Roberts, 2010), and a quantitative study that used two advanced estimation methods (i.e., standard and Zero-inflated Poisson (ZIP) regression models) to estimate the effects of SPS regulations on fresh fruit and vegetable imports (Peterson, Grant, Roberts, & Karov, 2013). Of these three studies, the descriptive works were published in the Journal of International Economic Law and a book on trade laws and health (Josling, Orden, & Roberts; Roberts) and the econometric study was published in the American Journal of Agricultural Economics. The point is: While Dr. Roberts is capable of doing advanced statistical work, she is not interested in causation in every study and publication.
Second, law librarians should ask: Can you articulate independent and dependent variables? Most researchers can articulate an outcome of interest, or dependent variable (e.g., child support awards), but only some are in a position to list the factors, or independent variables, that might affect the outcome (e.g., parent income). In newer fields, researchers might lack sufficient insights on possible independent variables. For instance, the law of disability benefits for long-haul COVID-19 impairments is unsettled (Bloomberg Law, 2022), and we do not yet know which factors will increase a claimant’s likelihood of a disability award. A researcher could credibly borrow independent variables from cases involving other long-term disabilities, such as multiple sclerosis. Other researchers might select a more open-ended, non-quantitative approach to the topic given its newness.
Third, law librarians should ask: Is there available or collectible data on this subject and/or population (see Chapter 4 on finding data)? For instance, data on appellate court judges and opinions is available through the University of South Carolina’s Judicial Research Initiative, Washington University in St. Louis’ Judicial Elections Data Initiative, the National Center for State Courts (NCSC)/Conference of State Court Administrators Court Statistics Project, and elsewhere. Researchers can also gather new data on appellate court opinions because those opinions “are now largely freely, publicly, and readily available in their entirety” (Carlson, Livermore, & Rockmore, 2020, p. 236) thanks to Public.Resource.Org, CourtListener, the Free Law Project, Harvard Law School’s Caselaw Access Project, the University of Michigan Law School’s Civil Rights Clearinghouse, and other open law initiatives (Carlson, Livermore, & Rockmore; Petrova, Armour, & Lukasiewicz, 2020; Schlanger & Lieberman, 2006).
By contrast, it can be difficult to obtain relevant, contemporary, and complete data on juveniles in the correctional system (Adams, 2021; Wolbransky, Goldstein, Giallella, & Heilbrun, 2013). In fact, scholars face increased research ethics board, or I.R.B., scrutiny for any study of individuals under 18 years of age (see Cwinn, Cadieux, & Crooks, 2021. Researchers face myriad roadblocks to conducting original research in prisons, schools, medical facilities, and other highly controlled sites. Law librarians can help patrons think through the availability of data, documents, and research subjects. This analysis is particularly important in quick turn-around research.
5.2 Legal Touchstone: Tyson v. Bouaphakeo
In recent years, the Supreme Court has wrestled with the admissibility of statistical evidence in class action suits. Employers have won many of these cases (e.g., Wal-Mart v. Dukes), but workers’ arguments persuaded the court in a 2016 food industry case. In Tyson v. Bouaphakeo (2016), the Supreme Court issued its opinion that statistical evidence was admissible to prove liability and damages in a class action lawsuit. The named plaintiffs were hourly employees at a Tyson pork processing plant. Under the Fair Labor Standards Act (FLSA), the plaintiffs claimed that Tyson failed to compensate them for overtime when donning and doffing protective equipment. Tyson did not keep records of donning and doffing times, so the plaintiffs relied on the representative analysis of an industrial relations expert to extrapolate statistical findings for the average times spent donning and doffing per plant department. Tyson first argued that the class could not be certified because certification assumed that all employees spent the same amount of time donning and doffing. Second, Tyson argued that damages awarded to the class might be distributed to employees who did not work uncompensated overtime. For a six-justice majority, Justice Kennedy wrote that statistical evidence is not categorically improper and could be used for class certification if the class members could have relied on the method to prove liability in an individual action (Hunton, 2022). Justice Thomas wrote a dissent joined by Justice Alito, which argued that the variability in donning and doffing times among class members was too great to satisfy the requirements for class representation. The Tyson court opened the door to statistical evidence in subset of class action suits.
Fourth, law librarians should ask: Is a quantitative approach better than the alternatives? Why? Quantitative research is a good choice when the researcher wants to generalize, or reduce complicated phenomenon to single numbers (e.g., a regression coefficient) or tables of numbers (Jenkins-Smith et al., 2017). Qualitative research is a better choice when researchers want to display people’s attitudes, values, practices, or truths broadly. Triangulated, or mixed-methods studies involving quantitative and qualitative techniques are optimal when researchers want to both reduce a phenomenon to numbers and also explicate the sentiment, thought processes, or arguments behind those numbers.
5.3 Sample questions for determining if quantitative analysis is feasible and desirable
Can the phenomenon that interests me be counted?
Can the phenomenon be counted given my resources (time, money, good will)?
Can the phenomenon be counted validly and reliably (see validity, reliability discussion below)?
Can I get the data when I need it?
Will the quantitative data inform my understanding of what interests me?
(Optional) Will the quantitative data be useful to decision-makers, stakeholders?
(Optional) Will the quantitative data complement or help explain my qualitative data?
What Data Should I Collect?
The world is full of data, and that fact can overwhelm newer researchers. Law librarians can help patrons navigate a series of terms, research practices, and decisions about what data to collect. This conversation should start with a review of the researcher’s hypothesis or research question. The H or RQ should indicate the pertinent people, places, policies, etc. and suggest what sort of data might be needed. In many cases, the patron will use the H or RQ to articulate the unit of analysis, population and sample.
Complex legal phenomena can be studied from a variety of angles. Federal drug policy, for instance, can be researched at the individual level (e.g., victim, offender, prison guard), small group level (e.g., gang, victim’s family, offender’s family), organizational level (e.g., court, re-entry program, school), and societal level (e.g., Congressional testimony, media coverage, surveillance technologies). Social scientists call these levels “units of analysis” (see Bhattacherjee, 2012).
5.4 Notes from the Desk of Sarah E. Ryan: Which unit of analysis explains Rwanda’s success?
From 2007-12, I researched community-building in Rwanda. The research sprang from conversations with a graduate school mentor about “positive deviance” [PD], or community-centered wisdom and problem solving (Singhal, 2010). Positive deviance theory and applied research assumes that innovation can come from poor and challenged communities. Positive deviance helps explain why some poor families, towns, and even nations fare better than others in similar situations. Rwanda seemed like a case study in positive deviance, or achievement against all odds. In the late 1980s, the global market for Rwanda’s main export—coffee—declined precipitously. Within a few years, the resulting poverty exacerbated Rwanda’s racialized inter-group tensions (Kamola, 2007). In 1994, the nation was torn apart by genocide. Following the genocide, Rwanda struggled to rebuild roads, homes, and social trust. But by the mid-2000s, the country boasted remarkable progress toward key goals, including increasing girls’ school attendance and women’s representation in government. I wanted to know Rwanda’s secret to rebuilding institutions and social ties. Because the nation is so small, I also wanted to know if the positive deviance approach could be applied on a level as large as the nation-state. I conducted three rounds of research, using different units of analysis. My first research project posited government rhetoric as a potential unifying force at the nation-state level, focusing on the use of “good governance.” The phrase was popular with the international development community (i.e., wealthy nation-states) in the 1970s; I wanted to know if Rwanda had successfully reclaimed good governance to unite policymakers and secure international project funding. My second research project focused on umuganda, or compulsory community labor and engagement, as a potential unifying force at the town or neighborhood level. Umuganda was a pre-genocide forced labor practice; I wanted to know if it had been rehabilitated into a productive structure for routine community work, discussion, and decision-making. My third research project concerned women’s agronomy associations, sub-neighborhood institutions, which focused on food security, jobs, and school fees and were led by women. Overall, my research showed that the strongest force for wisdom sharing and problem solving was the women’s agronomy associations. They were hyper-local, leveraged existing social networks, and operated outside of national and regional centers of power. Even though Rwanda is a small country, I found the seeds of change were several units of analysis smaller than the national or even town level. This aspect of positive deviance makes it difficult to scale or share across social units. It also suggests that we should support the good work of local change agents.
Once a patron decides on the unit of analysis, that decision can help answer questions such as: What data should I collect? and Where is the data? For instance, if the researcher wants to conduct an organizational study of post-incarceration re-entry programs for drug offenders, she should first determine which organization to study (e.g., the court, the public defender’s office, the prosecutor’s office). That determination will help the researcher determine where the data might be. Re-entry court data could be in the chambers of the judges running the re-entry programs, in the offices of the prosecutors stipulating requirements for those programs, etc. The unit of analysis should also clarify the population of interest to the researcher.
Most Hs and RQs will indicate a population of interest, such as individuals serving sentences for federal drug crimes. Populations can be people, institutions, and even document collections (e.g., First Step Act Circuit Court opinions from 2018-2020). Outside of censuses, systematic reviews, and small-population studies, few researchers aim to collect evidence from entire populations. Rather, researchers gather data from a sample, or subset of the studied people, documents, etc. using a sampling frame, or list of the individuals in the population.
5.5 Sara Benesh’s Westlaw sampling frame
Before collecting a sample, researchers need to identify a sampling frame, or list of every person, document, organization, etc. (Blackstone/Saylor Foundation, 2012). Finding a sampling frame can be challenging. In the 1970s, a telephone book was an adequate sampling frame for a town’s population, or at least its households, because most U.S. homes had a home telephone line. As cellular telephones replaced home phones, the telephone book became an unreliable frame. In U.S. court research, a ready sampling frame rarely exists. Professor Sara C. Benesh faced this issue in her dissertation research. Dr. Benesh completed her doctoral work under the direction of renowned scholar Harold J. Spaeth (i.e., of the Supreme Court database). A portion of Benesh’s dissertation research concerned the treatment of confessional evidence in federal appellate court decisions (Benesh, 2002). With no ready sampling frame, Benesh turned to the Westlaw topic-and-key number system. Westlaw, now a suite of Thomson Reuters research products, includes topical markers for reported cases (e.g., 92:k696 (Abortion and birth control), 4:157 (Health of patient; necessity)). Dr. Benesh realized that she could select certain key numbers related to confessions and then gather cases decided in certain years using the West Decennial Digests. While her strategy would not yield some unreported cases and many older cases (i.e., pre-1980s), her approach could be replicated by other scholars, enhancing the reliability of her research. And since many legal researchers, including judges and their clerks, use Westlaw to find cases to cite as precedent, Dr. Benesh’s sampling frame was contextually appropriate, increasing the validity of her research.
While there are many ways to sample (e.g., random, cluster, snowball; probability or nonprobability sampling; Jenkins-Smith, 2017), most researchers strive for ample and representative samples. First, the sample needs to be large enough for the research purposes. In inferential statistics (e.g., regressions), the sample is used to make educated and mathematically supported conclusions about the larger population (Mahbobi & Tiemann, 2015). Population size and the requirements of the selected statistical model inform sample size (see USAID, 2018). Researchers interested in studying national populations will be glad to know that a sample of 1,000-1,500 participants is often sufficient to represent a population of millions and to satisfy the requirements of most statistical models. On the smaller side, 100 individuals or instances is a good minimum for most statistical models.
The second major sampling issue is representativeness. A sample should reflect the diverse characteristics of its population; it should include documents or participants in similar proportions to the larger group (see Bhattacherjee, 2012). A corpus of 8th and 9th Circuit Court decisions would not represent the U.S. Circuit Courts. A sample of wealthy land-owners in Boston could not represent Bostonians. These examples are obvious, but most sampling issues are subtler. Law librarians can help patrons achieve representativeness through research and planning.
Before data collection, law librarians can help patrons define the population and find statistics on it (e.g., Circuit Court caseload statistics or Census Bureau datasets). With this information, the patron can better plan, anticipate sampling issues, and even redefine the population. Once sample data is collected, its summary statistics can be compared to population statistics to determine if the sample contains roughly the same proportion of subgroup participants, cases types, etc. If the sample is deficiently representative, the law librarian can point the researcher to textbooks that explain how to correct sample deficiencies (see Bhattacherjee; Jenkins-Smith et al., 2017). While unit of analysis and sampling considerations are much broader than “what data should I collect?,” they are indispensable in answering that formative methodological question. Similarly, issues of validity and reliability should be considered early and often.
How Should I Collect Or Capture The Data?
The data collection or capture portion of a study design is its heart, and involves myriad decisions (and often, compromises). Law librarians can help patrons navigate these decisions using four terms of art: instrument, validity, reliability, and levels of measurement. Law librarians can also review research instruments, including surveys.
Discussing Instrumentation
A research instrument is the data collection tool. Common quantitative instruments include electronic and paper surveys and content analysis coding forms (i.e., sheets that allow coders to record attributes of each document in a set, such as settlement amount). Emerging instruments include biometric testing devices, web-based simulation/virtual reality platforms, blogs, tweets, and other public and private born-digital content (see Braun, Clarke, & Gray, 2017).
While instrumentation design comes later in the research process than articulating the unit of analysis or population, law librarians can ask instrument questions to help researchers (re)consider basic assumptions of the study design. For instance, if the population is immigrants currently confined to civil detention centers, instrumentation questions could alert the researchers to the challenges of collecting data from detained individuals of diverse cultural and linguistic backgrounds. Logistically, the researchers might be better able to collect data from released detainees, a different population. Their instruments would still need to be culturally and linguistically appropriate. Cultural and linguistic appropriateness are two facets of validity.
Discussing Validity
Broadly, validity asks: Does the instrument measure what it is supposed to measure? A bathroom scale is a valid measure of body weight, but not of happiness, resilience, or fidelity. Instruments and their items are considered valid when they appear to measure what the researchers want to measure, can predict related outcomes like achievement or behavior, and/or correlate with other instruments, or items from within the current instrument, that are supposed to be measuring the same thing (Lane et al., 2003). For example, trust is a perennially difficult belief to measure. If researchers borrowed trust-in-staff items from surveys of college residence hall students for a survey of detained immigrants, they should expect validity questions from their readers because trust-in-staff likely means something different to individuals who cannot leave their housing facilities. Law librarians can ask validity questions to signal the need for further foundational research (e.g., to find existing, validated instruments) or the difficulties of collecting data as planned. Reliability questions will often come later in the research conversations.
Discussing Reliability
Broadly, reliability asks: Would this instrument or research process produce similar results if repeated? Most people use tape measures reliably. If two people measured a wall with the same tape measure, they might disagree by centimeters but would be unlikely to disagree by feet. This is because a tape measure requires little instruction or calibration; it is a reliable instrument in the hands of different people. By contrast, essay assessments are messy measurement tools.
Different graders routinely evaluate essays differently (Zhou & Huang, 2020). In a multimethodological study of how graders rated essays submitted for China’s standardized English-as-a-foreign language (EFL) exam, Zhou and Huang discovered unacceptable levels of grader difference, numerically represented as low reliability coefficients (Zhou & Huang). The researchers recommended two changes to increase reliability: 1) that students complete at least two essays, one of them a persuasive essay, and 2) that two independent graders grade each student’s essays (Zhou & Huang). The narrow goal of such changes would be more consistent inter-coder agreement. The broad goal would be ratings closer to students’ “true scores,” a common conceptualization of reliability (Lane, et al., 2003).
Whether we are measuring a wall or student achievement or plaintiff satisfaction with the court system, we want our procedures to succeed regardless of who is implementing them and to come as close as possible to measuring the truth. The pursuit of real world truth brings reliability and validity into conversation. Nevertheless, discussions about validity can occur early in the research process whereas discussions of reliability often require that the patron be far enough along to discuss the planned procedures and instruments. At that stage, we can also discuss levels of measurement.
Discussing Levels of Measurement
As researchers refine their instruments and data collection plans, they should ask: Will these tools/plans yield that sorts of data that I need for my analysis? Quantitative researchers need to pay attention to the levels of measurement, or levels of scale, in a data collection instrument because certain levels—e.g., interval-ratio—are needed for many statistical tests. Most social scientists divide measurements into three levels: nominal, ordinal, and interval ratio.
Nominal data have no value in real life. Rather, numbers are assigned for coding and counting purposes. For instance, a public library hosts an event for families and a librarian keeps a tally of how many adults and children attend. The tally sheet might have a hand-written A on the left, a hand-written C on the right, and tick marks under each letter. At the end of the night, the librarian adds up the tick marks in the columns to produce total counts of adults and children (i.e., represented as n adults, n children). But, she has no data beyond these numbers; no ages, neighborhoods, incomes, races, etc.
In social science research, race is a common nominal variable. Each racial category will be assigned a number (e.g., Asian=1, Black=2 Latino=3). The codes provide an easy short-hand for data collection and entry but they cannot be used in advanced statistical operations because they have no numerical meaning; one Asian person is not 1/3 of one Latino person even though the Asian person receives a 1 and the Latino a 3. If a researcher deploys a survey instrument comprised entirely of nominal questions, he will be able to calculate counts and mode (i.e., the category or value that occurs the most; e.g., we had more adults (A category) than children at the event) but will not be able to perform more advanced statistical analysis because those models assume a higher level of data.
Ordinal data are numerical values along a scale. They allow comparison of responses to the scale but do not reflect real world, incremental differences. For instance, satisfaction questions are typically ordinal and often presented as five point scales (e.g., Strongly satisfied=5, Satisfied=4; Neutral=3; Unsatisfied=2; Strongly unsatisfied=1). If one survey taker indicates a 2 and another a 4, that means that the first person is unsatisfied and the second is satisfied. We cannot say that the “4” person is twice as satisfied based upon the ordinal scores—he might be three times as satisfied!—but we can say he is more satisfied than the “2” person. Researchers can use ordinal data to calculate mode and median, or midpoint, but should not use them to calculate average/mean, since the numbers are relative to each other and their scale only. So, it is valid to report counts by category, such as: 42 respondents were strongly satisfied, 19 satisfied, 21 neutral, 7 unsatisfied, 3 strongly unsatisfied. It is also valid to report the modal category: strongly satisfied (n =42). It is also valid to arrange the scores from highest-to-lowest or vice versa and find the middle score. Here, there were 92 responses (=42+19+21+7+3) and the middle response was the 46th response, which fell in the satisfied category. Further conclusions—including about the average/mean score—require the highest level of data: interval-ratio.
Interval-ratio data have real world, numerical value. Interval-ratio items are used to record temperatures, incomes, damage awards, number of power plants, etc. Interval data, like Fahrenheit temperature, do not stop at zero and can have negative numbers (Lane et al., 2003). Ratio data cannot go below zero and zero indicates the absence of the phenomenon (Lane et al.). For instance, a man cannot have a negative number of children; if he has zero children he has no children. In social science research, the interval vs. ratio distinction rarely matters. So, most social scientists used the shorthand phrase interval-ratio to refer to data that expresses incremental, real world differences such as the difference between earning $45,000 per year and $145,000. Incremental data permits simple and advanced statistical operations and inferences such as population estimates based upon sample data.
5.6 Solar power data: Interval-ratio data permit simple and advanced operations and inferences
Interval-ratio data permit both simple mathematical comparisons and advanced statistical analysis, including inferential and predictive analysis. As of 2020, California had 10.6 gigawatts (GW) of small-scale solar photovoltaic (PV) capacity (U.S. Energy Information Administration, 2021). The next closest state, New Jersey, had roughly 10% of the capacity as California (U.S. Energy Information Administration). But New York, Massachusetts, and Arizona had both similar five-year ramp-up rates and 2020 capacity as New Jersey (U.S. Energy Information Administration). While slower to ramp-up than these states, Texas is now on a ramp-up curve faster than all leading states but California (U.S. Energy Information Administration). Using information from this dataset and treating 50 U.S. states as the population, researchers could create models to predict when Texas and other states would reach California-levels of PV capacity.
In addition to discussing reliability, validity, and levels of measurement, law librarians can provide a final data collection service: instrument review. Often, this will take the form of survey instrument review.
Reviewing Instruments
Research instruments take many forms. Coding instruments help content analyzers collect the same pieces of information from successive documents. Examinations help researchers assess the skill of test-takers. Surveys help researchers collect quantitative and qualitative data from participants. Survey instruments are frequently used by law librarians and their patrons to collect original research and quality improvement data. Empirical legal research specialists should know how to offer feedback on a draft survey.
During survey instrument review, law librarians can scan for three common issues: double-barreled statements, non-exhaustive item/answer choices, and overlapping item/answer choices. First, survey writers can inadvertently ask for more than one piece of information in a single question or item, making it more difficult to answer and less valid. These questions are double barreled and should be re-written. For instance, in a patron survey: Do you like coming to the law library in the afternoon to study? The question contains two possible truths: afternoon and study. If Agnes comes by the law library in the afternoons to check out fiction books, how should they answer the question? Assuming that the law library uses advanced survey software that can use Agnes’ initial answer to populate text in a subsequent question, Agnes could more accurately record their preferences via two questions: 1) During weekdays, what time of day do you prefer to come to the law library? (choices: morning, afternoon, or evening); and 2) What typically brings you to the law library in the [Agnes’ choice: afternoon]? Double-barreled issues arise in the wording of individual survey items whereas non-exhaustive and overlapping choice issues arise in prepopulated answer choices.
Most surveys include questions with prepopulated choices (e.g., More satisfied, satisfied…). Two issues tend to plague such lists. First, survey writers do not imagine or provide a full list of choices; this is the problem of non-exhaustiveness. For example, a law library asks students to indicate their program—JD, LLM, Dual Degree—but forgets to include a category for certificate students, such as an attorney completing a Human Rights certificate. The obvious fix is to update the choices it include every category of student at the law school; some survey writers add an “other” category with a fillable blank for atypical or unexpected responses.
Second, survey writers create overlapping categories. For example, a legal researcher wants to collect age information and creates categories: a) below 18, b) 18-25, c) 25-30, d) 30-35…. A 25 year old respondent could correctly select choice b or c because 25 overlaps both. Most research methods textbooks describe this as a failure of mutual exclusivity. To make the categories mutually exclusive, the survey writer simply needs to adjust the start of categories c, d, etc. Better yet, the researcher could transform the item into a more numerically-powerful interval-ratio question: How old are you?
Beyond these problems, surveys can have many more issues. They can be too long and produce respondent fatigue or abandonment. They can ask respondents to perform unclear tasks. They can be biased. Librarians can scan for double-barreled, non-exhaustive, and overlapping items as a way to spark a conversation and to recommend that the researcher try the instrument out, or pilot test, with actual humans.
How Should I Manage Data?
Data management is a library specialty. Some libraries have data management units, but all librarians should be able to discuss the basics of data management with their patrons, including data storage, cleaning, and preservation. Law librarians can use the data lifecycle and research budgeting to ground these conversations.
First, law librarians can teach patrons about the data lifecycle. As depicted in the open access graphic created by the LMA Research Data Management Working Group at Harvard Medical School, the data lifecycle begins with a plan and ends with data access, preferably open access. Early in the process, researchers should set file naming conventions. Mid-process, researchers should deploy and refine collaborative data analysis systems (e.g., multi-user statistical software). Late in the process, researchers should examine how the data appears in article pre-prints. Law librarians can ask patrons to walk them through the data lifecycle of the current project so that the librarians can understand which parts of the lifecycle are relevant, what issues might arise, and how the research-library team can troubleshoot data management.
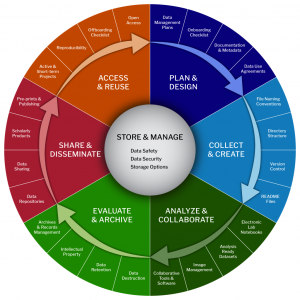
5.7 The Data Lifecycle, by LMA Research Data Management Working Group, used with attribution per CC BY-NC 4.0
Relatedly, and as detailed in Chapter 6, law librarians can discuss research budgeting with their patrons. These conversations can help patrons understand the costs of data management, particularly for research that requires advanced computing power and/or data storage (e.g., terabytes of data). Every type of quantitative research can be performed in a more or less costly manner. Cost conversations can help patrons to strategize and economize data cleaning, sharing, analysis, reporting, and more.
How Should I Analyze and Report the Data?
Data analysis and reporting occur at the mid- and late-points of a quantitative research project. Quantitative data analysis is the subject of innumerable research methods and statistics textbooks (e.g., Lane et al., 2003; Mahbobi & Tiemann, 2015; Jenkins-Smith et al., 2017). Statistical model selection falls outside of core law library services, but the presentation of quantitative results is an aspect of scholarly communication services.
5.8 Law Librarian Spotlight: Joe Cera
With a background that includes engineering, physics, and law, Joe Cera contributes a unique perspective to the field of law librarianship. He is a national expert in legal citation analytics, Wikidata, and legal repository building (see Cera, 2021, 2022). Mr. Cera coaches law librarians in managing Wikidata and incorporating linked data into their work (Cera, 2022). As the Digital Initiatives and Scholarly Communications Librarian at the University of California Berkeley’s Law Library, Mr. Cera tests the capabilities of existing library services and envisions alternatives for the future. After earning a bachelor’s degree in physics from Arizona State University, Mr. Cera obtained a law degree from the University of Minnesota, and an MLIS from the University of Washington, where he worked in the Marian Gould Gallagher Law Library. Before joining the Berkley Law Library, he also worked at the California Judicial Center Library. Mr. Cera’s long-term goals are to show that technology development is safer and better managed by law librarians than external commercial businesses, and that law librarians can further increase the accessibility of public data. In the meantime, he encourages law librarians to research and troubleshoot unfamiliar areas of technology to build our data skills. (Cera, 2022).
When our patrons request a reference consultation for data analysis or scholarly reporting, we should first ask about the foundational aspects of the research project, such as what data was collected and how it was collected. Only then can we understand the work well enough to advise them on where to look next. Research methods textbooks and empirical research articles can guide researchers to commonly accepted data reporting practices, such as how to represent quantitative findings (e.g., as R2/regression coefficients) and discuss their statistical strength (e.g., p value). Most universities also have data labs or statistical resource people to discuss software choices—e.g., R, SAS, SPSS, Stata—and troubleshoot software issues with patrons. Troubleshooting can include the production of properly-formatted data tables for journal articles. Many times, patrons are unaware that such resources exist to help them effectively analyze their data and report their findings.
Reflection Questions
- Prior to reading this chapter, what was your understanding of the data lifecycle? Has your understanding changed? If so, how? If not, which facts or ideas in this chapter reinforced your existing understanding?
- Do you have experience designing surveys? If yes, what lessons has this experience taught you? If no or not yet, how could you gain additional survey design skills?
- In general, have you found open access textbooks to be of equal, greater, or lesser value than commercial textbooks? Select one of the open access textbooks referenced in this chapter and skim its content. How does it compare to your expectations of typical textbooks for that subject?
- In your opinion, where should law librarians draw the line in their quantitative services and recommendations? Why is this the right boundary for services?
References
Adams, B. (2021). Advancing the collection of juvenile justice data. National Institute of Justice, https://www.ojp.gov/pdffiles1/nij/255642.pdf
Anbari, A. B., Wanchai, A., & Graves, R. (2020). Breast cancer survivorship in rural settings: A systematic review. Supportive Care in Cancer, 28(8), 3517-3531.
Bavli, H. J., & Felter, J. (2018). The admissibility of sampling evidence to prove individual damages in class actions. Boston College Law Review, 59(2), 655-724.
Benesh, S. C. (2002). The U.S. Court of Appeals and the law of confessions: Perspectives on the hierarchy of justice. LFB Scholarly Publishing LLC.
Bhattacherjee, A. (2012). Social science research: Principles, methods, and practices. Center for Open Education/University of Minnesota’s College of Education and Human Development. https://open.umn.edu/opentextbooks/textbooks/79
Blackstone, A./Saylor Foundation. (2012). Principles of sociological inquiry – qualitative and quantitative methods. Center for Open Education/University of Minnesota’s College of Education and Human Development. https://open.umn.edu/opentextbooks/textbooks/principles-of-sociological-inquiry-qualitative-and-quantitative-methods
Braun, V., Clarke, V., & Gray, D. (2017). Collecting qualitative data: A practical guide to textual, media and virtual techniques. Cambridge University Press.
Carlson, K., Livermore, M. A., & Rockmore, D. N. (2020). The problem of data bias in the pool of published US appellate court opinions. Journal of Empirical Legal Studies, 17(2), 224-261.
Cera, J. (2021, October 3). The benefits of having your own sandbox. Cardozo Law. https://larc.cardozo.yu.edu/sandbox-series/sandboxseries/series3/2/
Cera, J. (2022). Persistent identifiers 101 [Webinar]. AALL Law Repositories Caucus. https://larc.cardozo.yu.edu/his-hig/recordedsessions/recordedsessions/3/
Cera, J. (2022, July). Personal communication with Adrienne Kelish [attorney and law librarianship student and research assistant at the University of North Texas].
Cwinn, E., Cadieux, C., & Crooks, C. V. (2021). Who are we missing? The impact of requiring parental or guardian consent on research with lesbian, gay, bisexual, trans, two-spirit, queer/questioning youth. Journal of Adolescent Health, 68(6), 1204-1206.
Freire, P. (2018). Pedagogy of the oppressed [50th Anniversary ed.]. Bloomsbury Academic.
Hall, M. A., & Wright, R. F. (2008). Systematic content analysis of judicial opinions. California Law Review, 96(1), 63-122.
Hessick, C. B., Wright, R. F., & Pishko, J. (2022, forthcoming). The prosecutor lobby. Washington and Lee Law Review.
Hicks, P. D. (2019). The Litchfield Law School: Guiding the New Nation. Easton Studio Press LLC.
Hunton Andrews Kurth. (Winter, 2022). The brief: Financial services litigation quarterly. https://www.huntonak.com/images/content/8/1/v2/81595/The-Brief-Winter-2022.pdf
Jenkins-Smith, H. C., Ripberger, J. T., Copeland, G., Nowlin, M. C., Hughes, T., Fister, A. L., Wehde, W. (2017). Quantitative research methods for political science, public policy and public administration: 3rd Edition with applications in R. University of Oklahoma/OU University Libraries, https://shareok.org/handle/11244/52244
Josling, T., Orden, D., Roberts, D. (2010). National food regulations and the WTO agreement on sanitary and phytosanitary measures: implications for trade-related measures to promote health diets. In C. Hawkes, C. Blouin, S. Henson, N. Drager, & L. Dubé (Eds.) Trade, food, diet and health: Perspectives and policy options (pp. 219-237). Food Research Institute.
Kamola, I. A. (2007). The global coffee economy and the production of genocide in Rwanda. Third World Quarterly, 28(3), 571-592.
Lane, D. M., Scott, D., Hebl, M., Guerra, R., Osherson, D., & Zimmer, H. (2003). Introduction to statistics. Center for Open Education/University of Minnesota’s College of Education and Human Development. https://open.umn.edu/opentextbooks/textbooks/459
Lillian Goldman Law Library, Yale Law School. (n.d.) All known digitized Litchfield student notebooks, https://documents.law.yale.edu/litchfield-notebooks/digitized
LMA Research Data Management Working Group. Research data lifecycle [and checklist]. https://datamanagement.hms.harvard.edu/about/what-research-data-management/biomedical-data-lifecycle
Mahbobi, M., & Tiemann, T. K. (2015). Introductory business statistics with interactive spreadsheets – 1st Canadian Edition. BC Campus/OpenEd https://opentextbc.ca/introductorybusinessstatistics/
Mann-Jackson, L., Simán, F. M., Hall, M. A., Alonzo, J., Linton, J. M., & Rhodes, S. D. (2022). State preemption of municipal laws and policies that protect immigrant communities: Impact on Latine health and well-Being in North Carolina. INQUIRY: The Journal of Health Care Organization, Provision, and Financing, 59, doi: 00469580221087884.
Peterson, E., Grant, J., Roberts, D., & Karov, V. (2013). Evaluating the trade restrictiveness of phytosanitary measures on US fresh fruit and vegetable imports. American Journal of Agricultural Economics, 95(4), 842-858.
Petrova, A., Armour, J., & Lukasiewicz, T. (2020). Extracting outcomes from appellate decisions in U.S. state courts. In S. Villata, J. Harašta, & P. Křemen (Eds.), Legal knowledge and information systems (pp. 133-142). IOS Press Ebooks, https://ebooks.iospress.nl/volume/legal-knowledge-and-information-systems-jurix-2020-the-thirty-third-annual-conference-brno-czech-republic-december-911-2020
Rice, M., Broome, M. E., Habermann, B., Kang, D. H., & Davis, L. L. (2006). Implementing the research budget. Western Journal of Nursing Research, 28(2), 234-241.
Roberts, D. (1998). Preliminary assessment of the effects of the WTO agreement on sanitary and phytosanitary trade regulations. Journal of International Economic Law, 1(3), 377-405.
Roth, S., Nace, T., Brintzenhoff, J., Castello, O. G., Nova, V., Pierce, J., Tagge, N., Eger, C., & Dean, W. (n.d.). Systematic reviews & other review types [research guide]. Temple University Libraries, https://guides.temple.edu/c.php?g=78618&p=4251234
Rutten, G., & van der Wal, M. J. (2014). Letters as loot: A sociolinguistic approach to seventeenth- and eighteenth-century Dutch. John Benjamins Publishing Company.
Schlanger, M., & Lieberman, D. (2006). Using court records for research, teaching, and policymaking: The Civil Rights Litigation Clearinghouse. UMKC Law Review 75(1), 153-167.
Singhal, A. (2010). Communicating what works! Applying the positive deviance approach in health communication. Health Communication, 25(6-7), 605-606.
Singhal, A., & Rattine-Flaherty, E. (2006). Pencils and photos as tools of communicative research and praxis: Analyzing Minga Perú’s quest for social justice in the Amazon. International Communication Gazette, 68(4), 313-330.
Tyson v. Bouaphakeo, 577 U.S. ___(2016). https://www.supremecourt.gov/opinions/15pdf/14-1146_0pm1.pdf
USAID [United States Agency for International Development]. (2018). Population-based survey sample size calculator: Companion to the 'feed the future' population-based sampling guide. https://www.usaid.gov/documents/1866/population-based-survey-sample-size-calculator U.S. Energy Information Administration. (2021). Texas and Florida had large small-scale solar capacity increases in 2020. https://www.eia.gov/todayinenergy/detail.php?id=46996
Wal-Mart v. Dukes, 564 U.S. 338 (2011).
Wolbransky, M., Goldstein, N. E., Giallella, C., & Heilbrun, K. (2013). Collecting informed consent with juvenile justice populations: Issues and implications for research. Behavioral Sciences & the Law, 31(4), 457-476.
Wright, R. F., & Levine, K. L. (2021). Models of prosecutor-led diversion programs in the United States and beyond. Annual Review of Criminology, 4, 331-351.
Zhao, C., & Huang, J. (2020). The impact of the scoring system of a large-scale standardized EFL writing assessment on its score variability and reliability: Implications for assessment policy makers. Studies in Educational Evaluation, 67, 100911.
